Secure by Design
Learn more 
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
Connect with Us
MLSecOps Community
Join a growing community of AI security practitioners.
Huntr
Join the world’s first bug bounty platform for AI/ML.
Follow us on LinkedIn for the latest company updates and content.
MLSecOps Podcast New Episode

Hacktivity Leaderboard
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
If you are not already working on a project leveraging some form of AI or ML, the odds are very good that you soon will. "77% of business leaders fear they are already missing out on the benefits of generative AI" -CIO.com, so if you aren't actively working with AI systems yet, now is a great time to get started, and learn how to do so in a secure way. At Protect AI we are leading security for AI/ML by developing and maintaining OSS tools that detect vulnerabilities in ML systems. These are freely available via Apache 2.0 licenses to Data Scientists, ML Engineers, and AppSec professionals. We invest in Open Source tools to help you make meaningful improvements in your security posture. Each of our tools target a specific area that is vulnerable. This guide provides examples of threats you might encounter, a quick primer on our tools, how to use them effectively, and material for scaling your adoption of AI with them.
One specific threat we'll talk about is the risk of a Model Serialization Attack . It is a simple attack that embeds any arbitrary malicious code inside a Machine Learning(ML) model that is executed whenever the model is loaded for any use. In the real world we've seen examples of this being used to quickly grab the content of your SSH Keys, AWS Credentials, and other sensitive local secrets, encode them with base64, and simply ship them to an external endpoint via a simple DNS request. The code to perform this attack was just a few lines, and would never be seen under normal usage of loading a model to test, to fine-tune, or deploy.
If you listen to ONE piece of advice here, USE MODELSCAN NOW! The caps and bold may seem dramatic, but this is the easiest win for you in ML Security.
You wouldn't run an executable or PDF from the web without scanning it for viruses, similarly you shouldn't trust models either.
The steps to use this tool couldn't be easier:
Install ModelScan into your environment:
pip install modelscan
Run ModelScan before using any model you download from anywhere:
modelscan -p /path/to/model_file.h5
Or if you're using a model from HuggingFace, you can run it before you even download the model:
modelscan -hf keras-io/structured-data-classification-grn-vsn
OK, you know how to use it, but what exactly is it doing?
Earlier I explained a brief summary of Model Serialization Attacks . ModelScan is our tool to scan for those over most major Machine Learning Model formats, it is the first tool available to do so, and it is available in a commercially friendly license so that you can embed it into your work very quickly and easily.
In a few more words than earlier; Machine Learning models (traditional or LLMs), are distributed around using a process called serialization. Serialization takes an object from the memory of one computer, and writes it to a file that can be distributed to other machines. What makes this process special is that in many cases you can embed additional code to be executed automatically on load at the same time. Models therefore aren't just the weights that are needed to process a prediction or request, but can also include arbitrary code that is invisible to you before it executes.
To see how trivial it is to create a compromised model, view our demo: here.
These exploits can run at inference time in production, locally when testing, fine-tuning, or doing transfer learning, or at any point where the models are loaded using ML Libraries. Keep yourself, and all those around you safe by scanning model files.
ModelScan is the only tool to support most major model formats and we're working to support even more frameworks, tools, and to provide deeper insights when it spots a problem, in addition to embedding this into your ML pipelines and deployment checks, if you run into issues or have ideas to make it better, please reach out.
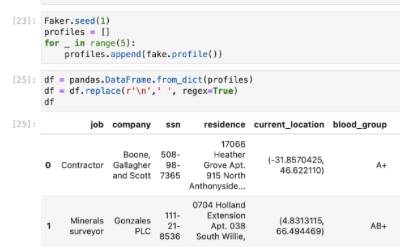
The foundation of most Machine Learning projects starts in a Jupyter environment, a workbook like interface where cells can contain arbitrary code from a variety of languages, shell commands, and even markdown formatted text to guide the reader through the work being explored. The notebooks in Jupyter are a fundamental tool for learning, sharing findings, and iterating on concepts quickly before migrating to more mature tooling.
Our first project was NB Defense, a plugin for your Jupyter environments or your command line to scan the content of Jupyter Notebooks for PII, security tokens, CVEs within dependencies, and compliance with 3rd party licenses. All of those tasks are not unique to Jupyter Notebooks and existing tools have worked to solve these problems for years. The challenge was how to tackle them in a way for Jupyter users to understand.
As a Jupyter user, a notebook to you looks something like this:
A series of cells and their outputs, however to the existing tools in the world your notebook looks like this:
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Setup"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"!pip install -q modelscan"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"!pip install -q tensorflow==2.13.0\\\\n",
"!pip install -q transformers==4.31.0\\\\n",
"!pip install -q matplotlib==3.7.2"
]
},
{
"cell_type": "code",
"execution_count": 3,...
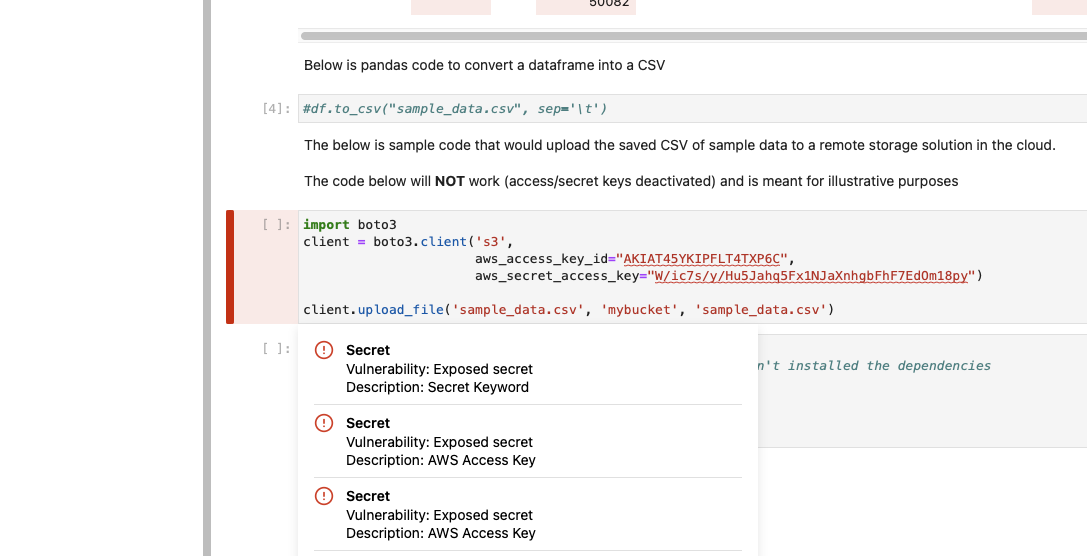
Simply JSON. When reports came back from those tools, they referred to a specific line in a JSON file, requiring you to figure out exactly how those entries mapped to your notebook, and to work to figure out how to correct the issue.
NB Defense takes a very simple approach; creates a representation of the content of the notebook that those tools can understand, creates an extensible surface to connect them to the notebook, then shows the results back to the user where they are in the notebook like this:
These are specific insights, right where you are in your notebook, and the same works for a CLI as well allowing you to embed this tool into your pre-commit hooks or other tools to run before work is shared.
We all try to take security carefully, but a simple mistake could leak AWS credentials, patient data (PII), etc to a peer before we even think about it. Running a tool like NB Defense in your workspace solves this risk for you and better protects everyone.
Embed NB Defense into your Jupyter environments and you can extend it with custom security tooling of your choosing. If you have specific questions, please reach out! Also if you'd like to add something to the list of defaults or see something we've missed, follow along here to contribute to the project or provide feedback.
Perhaps you aren't an ML Practitioner and you focus on AppSec, or you have someone in the field you care about. For you we provide AI Exploits. This is a collection of tools to quickly test for known critical exploits in MLflow, Ray, and H20.ai(All very popular MLOps tools). The exploits can be executed using Metasploit or Nuclei by loading the scripts into your existing tooling.
You can quickly evaluate if your instances of MLflow, Ray, or H20.ai are vulnerable to issues that lead to remote code execution, remote shells, and file replacement attacks that load alternative models, steal your existing ones, etc. For a breakdown of many of the bugs like this you can view our Threat Research Monthly Reports.
Each of these exploits target a vulnerability found by our crowd sourced bug bounty program Huntr, and package maintainers have worked to resolve the issues(or provided their reasons for not). Showing how these attacks work, and enabling you to validate issues quickly is the best way to bring attention to the risks, and to improve your security posture within MLSecOps.
Reading this blog was just your first step, next think through your work and where these tools can be used to allow you to leverage AI and ML technology securely.
For example, if you're regularly exploring new LLMs from the web, scan them with ModelScan before loading them to test and use. Or add NB Defense to your pre-commit hooks to ensure you don't share a notebook with a vulnerable dependency included.
Work with your peers to establish best practices for running our tools and others like them at scale within your organization, blogs, lunch and learns, and lighting sessions are all great ways to do that.
To keep up with what we're doing and the work of thousands of others join our MLSecOps community, or if you're itching to find new vulnerabilities within many of the Open Source supply chain for AI/ML, join huntr.
PS Remember: SCAN YOUR MODELS BEFORE USE!