Secure by Design
Learn more 
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
Connect with Us
MLSecOps Community
Join a growing community of AI security practitioners.
Huntr
Join the world’s first bug bounty platform for AI/ML.
Follow us on LinkedIn for the latest company updates and content.
MLSecOps Podcast New Episode

Hacktivity Leaderboard
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
Machine Learning(ML) Models are shared over the internet, between teams, and are used to make critical decisions. Despite this, models are not scanned with the rigor of a PDF file in your inbox.
This needs to change, proper tooling is the first step.
We are thrilled to announce: ModelScan. An open source project that scans models to determine if they contain unsafe code. It is the first model scanning tool to support multiple model formats. ModelScan currently supports: H5, Pickle, and SavedModel formats. This protects you when using PyTorch, TensorFlow, Keras, Sklearn, XGBoost, with more on the way.
To expand the functionality of ModelScan, we welcome community contributions. In that vein, we were heavily inspired by Matthieu Maitre who built PickleScan, THANK YOU! We hope our derived works expand on your vision and make you proud.
If you already know what Model Serialization Attacks are, and how they put you at risk; use the two snippets below to install ModelScan and scan your models before use.
# Install ModelScan:pip install modelscan# Scan a Model:modelscan -p /PATH_TO/YOUR_MODEL.h5
Your scan will complete in moments:
For everyone else, let's start with an explanation of a Machine Learning Model. A model is just a file or series of files that contain a few things: vectors(the main data structure), algorithms, and optionally layers and transformations. The purpose of the model is to encapsulate everything that is needed to generate or predict things with the model.
Model formats that store code within the files themselves create this threat surface. Unfortunately, most of the popular model formats support code storage. This puts the risk on everyone(you) who is using these models. To understand the risk, you need to know how models can be exploited in this manner.
Models are created from automated pipelines, others may come from a data scientist’s laptop. In either case the model needs to move from one computer to another before it is used and widely adopted. That process of exporting a model is called serialization, it is what packages the model into a specific files for others to use.
A Model Serialization Attack is where malicious code is added to the contents of a model during serialization(saving) before distribution — a modern version of the Trojan Horse.
The attack functions by exploiting the saving and loading process of models. For example, when you load a model with model = torch.load(PATH), PyTorch opens the contents of the file and begins to running the code within. The second you load the model the exploit has executed.
A Model Serialization Attack can be used to execute:
A thorough explanation of how attacks like this can be constructed and avoided is found in our deep dive: here.
Treat models as any other digital artifact, consider their source.
If all of your models are created in house, you trust all of the data scientists and machine learning engineers working and operating these systems, then you may consider your risk relatively small. However, insider threats exist, supply chain attacks on the open source foundations of ML happen, therefore there is risk.
If any models arrive in your organization from the web, then your total threat area has expanded. Even with everyone doing their best, the chance of an attack is now much higher.
You are vulnerable to this type of attack if you are loading models that were serialized in a format that supports code execution(most of them).
Importantly, a Model Serialization Attack is not detected by traditional anti-virus/malware solutions and require additional tooling for protection.
Your choice of machine learning framework or model provider may require a format that supports code execution. Often there is a tradeoff between security and convenience, making an informed choice strengthens your security posture.
If you can, adopt safe formats that do not store any code. This will prevent the attack but they may not be entirely possible to adopt. That is why we built and released ModelScan.
ModelScan does not load the model and execute the code automatically, it loads the contents into memory and searches for unsafe code operations used in model serialization attacks. This approach keeps your environment totally safe even with a potentially compromised model. Additionally it is fast, evaluating many models in seconds.
Ad-hoc scanning is a great first step, please drill it into yourself, peers, and friends to do this whenever they pull down a new model to explore. It is not sufficient to improve security for production MLOps processes.
Model scanning needs to be performed more than once to secure the model through its lifecycle, we recommend that you:
The red blocks below highlight this in a traditional ML Pipeline:
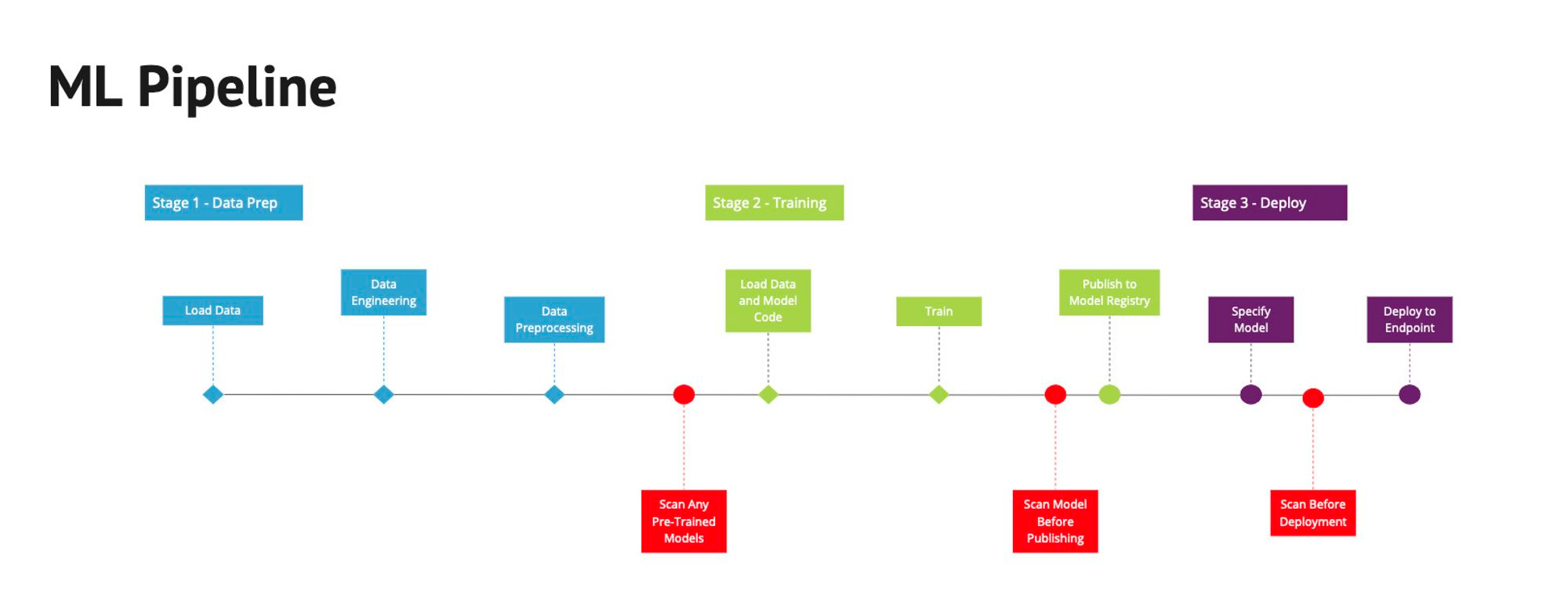
Inside ML Pipelines you will embed a script that runs the following command per model before retraining, publishing to a registry, and before deployment:
modelscan -p /PATH_TO/YOUR_MODELThis will take seconds to run on most models, and less than a few minutes on some of the largest LLMs available today.
This is the output if issues are found:
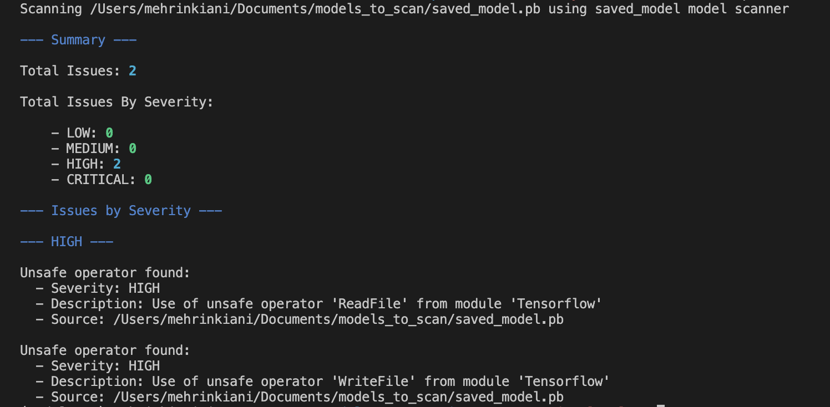
If an issue is found within the model, reach out to the creators of the model before using it to understand why they are delivering unsafe code. Do not use the model without a thorough investigation.
Implementing those processes to your MLOps practice is a great step to expanding your practice to MLSecOps and embedding security as effectively there as your traditional application development practices.
Not all models in your environment come from your pipelines, and many are loaded to explore and better understand other approaches. They are still capable of compromising your security. ModelScan is built to work locally for your data scientists and other engineers as well.
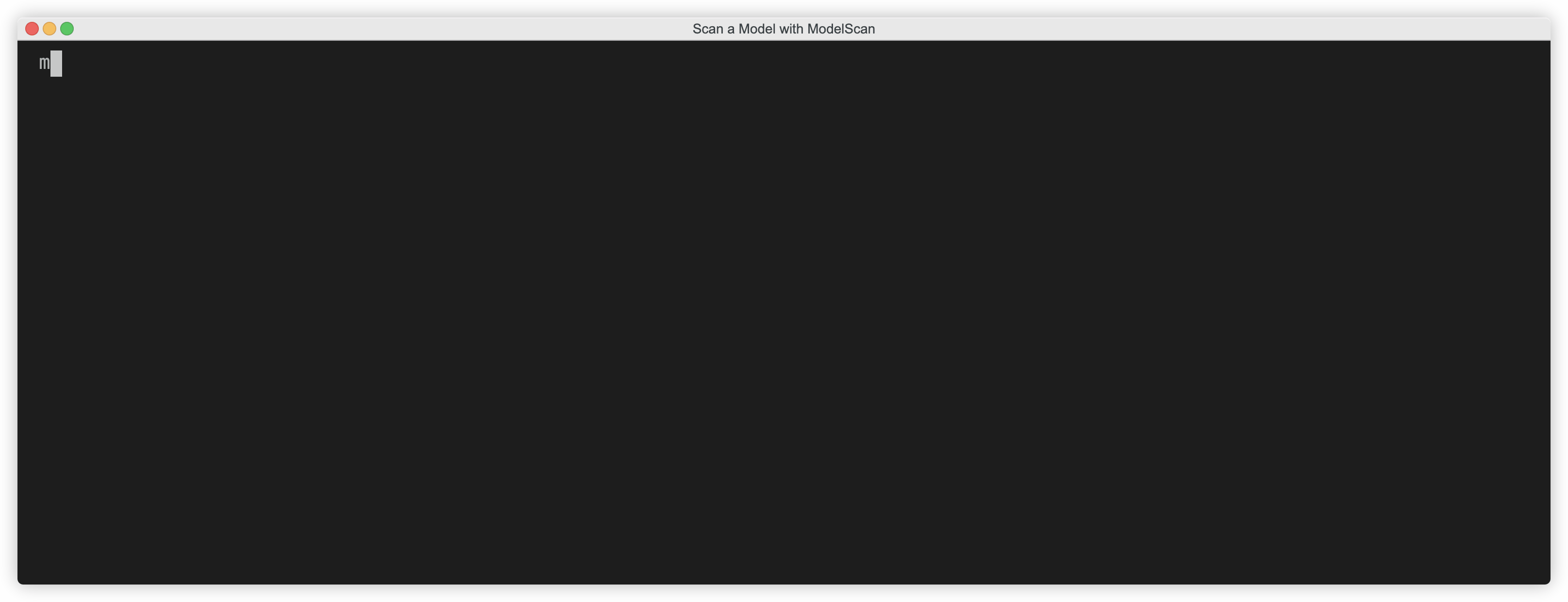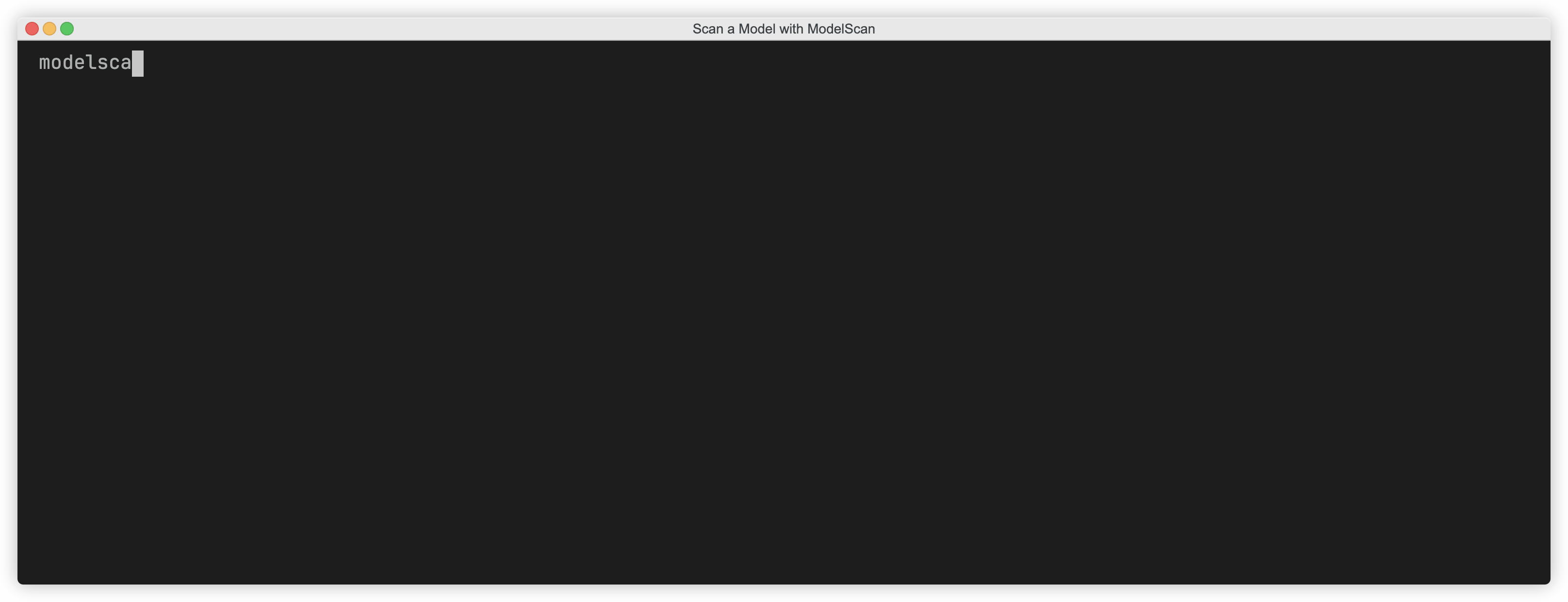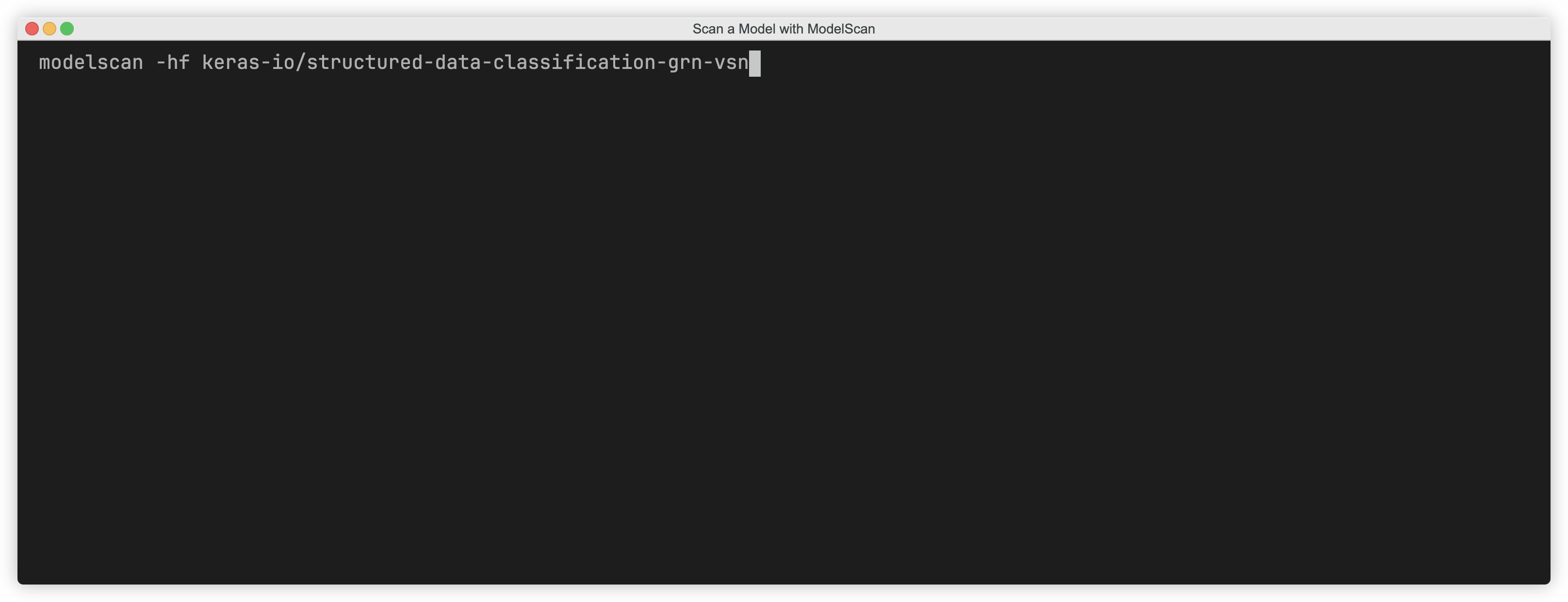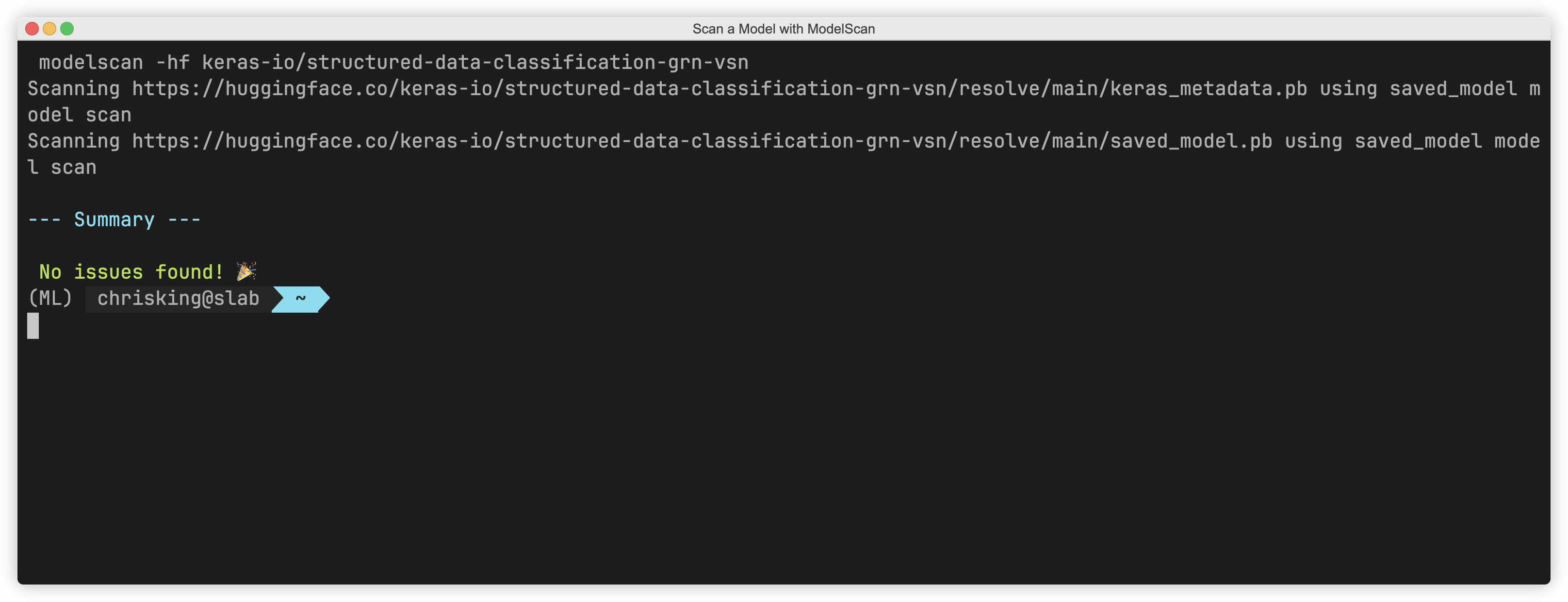
When a data scientist starts to explore a new model from HuggingFace, make it second nature for them to scan the model before use. We’ve made it easy with direct HuggingFace support:
# Scan the model `structured-data-classification-grn-vsn` from Keras-IOmodelscan -hf keras-io/structured-data-classification-grn-vsn
ModelScan can secure your ML pipelines, inference endpoints(at any stage), and data science environments without restricting creativity or performance.
Implementation can be done in just a few minutes.
For the latest installation instructions, code samples, and documentation check out the project on GitHub: https://github.com/protectai/modelscan.
Together we improve machine learning security, and help build a safer AI-powered world.
Seriously, scan any model you don't trust before loading it for use.