Secure by Design
Learn more 
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
Connect with Us
MLSecOps Community
Join a growing community of AI security practitioners.
Huntr
Join the world’s first bug bounty platform for AI/ML.
Follow us on LinkedIn for the latest company updates and content.
MLSecOps Podcast New Episode

Hacktivity Leaderboard
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
Change is underway at OpenAI. In the wake of a significant leadership shift, the company’s CTO and co-founder, Mira Murati, has joined a wave of departures, leaving Sam Altman as the last remaining founder. Alongside this exodus, OpenAI is pivoting toward a for-profit model, sparking even more discussion about its future. Amidst these sweeping changes, the release of the new "Strawberry" models has grabbed attention. This latest innovation introduces a "chain of thought" mechanism, allowing the model to solve problems step by step before delivering answers—marking a new approach in AI development.
Yet, as these headlines swirl, one surprising detail has emerged: OpenAI has quietly begun banning users. We took a closer look at how these bans are being carried out and noticed that other companies are beginning to adopt similar approaches.
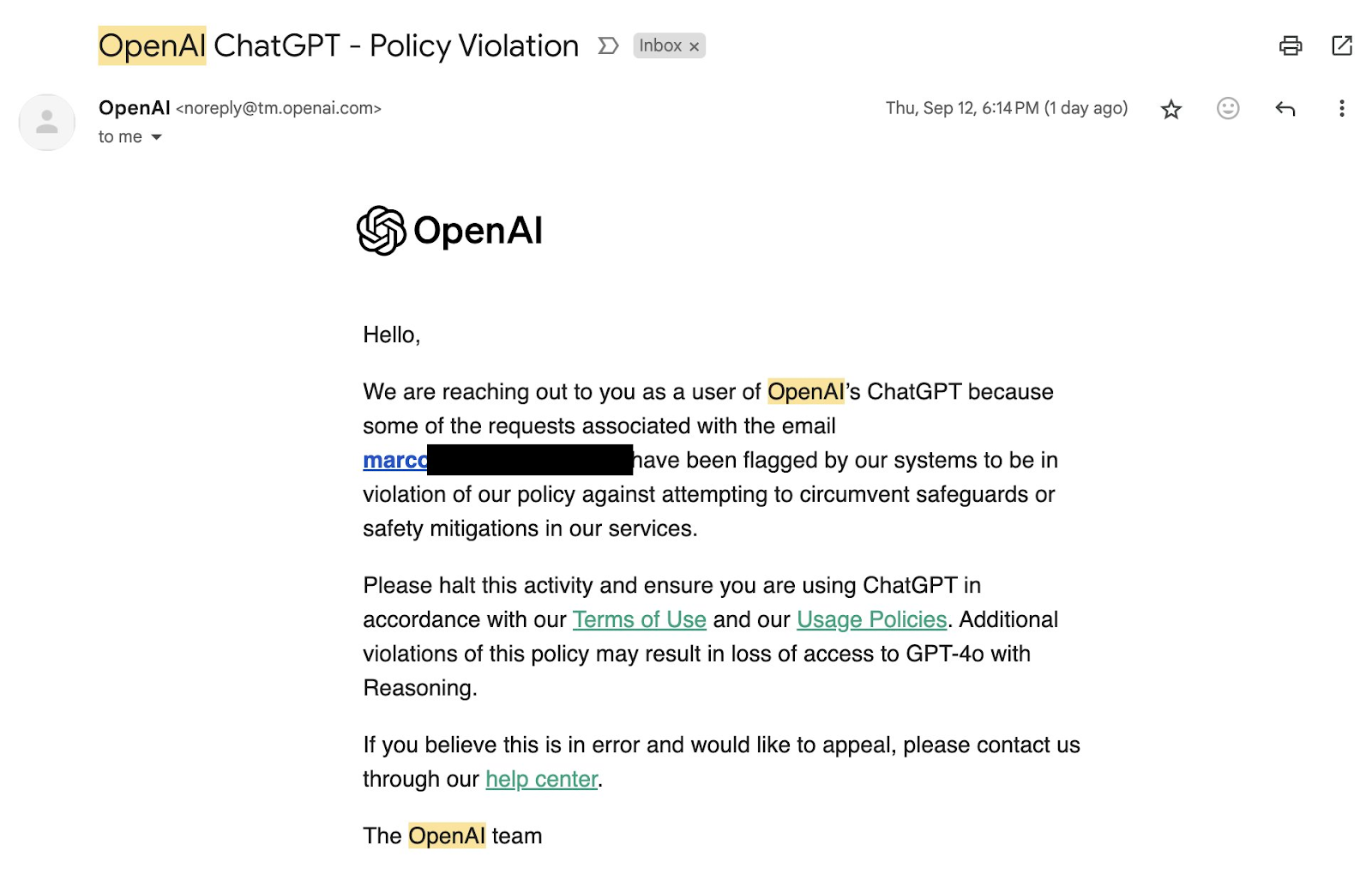
OpenAI is now banning users who attempt to uncover what its latest AI model is “thinking.” Since the launch of its "Strawberry" AI model family, which boasts advanced reasoning capabilities through the o1-preview and o1-mini versions, the company has issued warning emails and threats of bans to users who try to probe too deeply into how the model works.
While users can view the model's chain-of-thought process in the ChatGPT interface, OpenAI deliberately hides the raw data behind that reasoning. Instead, the displayed reasoning is filtered and interpreted by a secondary AI model, keeping the original process out of reach.
Several users have tried to bypass these restrictions through prompt injections and jailbreak techniques to access the raw chain of thought. In response, OpenAI has been sending warnings, threatening to ban those who continue these probing efforts.
Marco Figueroa received a ban warning
The reason behind OpenAI's strict yet controversial (due to hidden reasoning tokens) stance is to prevent other actors or model developers from gaining valuable insights into the model's reasoning process, which could be used to advance their own AI systems. It’s important to note that these warnings and potential bans are being issued after users breach the company's policies, implying that OpenAI monitors for prompt injections and jailbreaks asynchronously through out-of-line scanning, beyond the basic, in-line guardrails typically in place.
While many LLM firewall vendors rely on real-time detection and blocking through gateways or reverse proxy approaches, the largest foundational model providers—those with the highest usage globally—are adding out-of-line threat scanning of user interactions. Rather than placing all checks in-line like traditional LLM firewalls or guardrails, these providers are increasingly scanning user inputs and outputs asynchronously. This seems true for players like OpenAI, as explained before in the example on chain-of-thought reasoning, which likely requires more comprehensive scanning beyond basic in-line guardrails.
Our belief is that out-of-line scanning offers better scalability to complement a limited set of in-line checks, which often introduce performance challenges, particularly in terms of cost and latency. We have discussed this extensively in our analysis of security approaches beyond firewalls, where we advocate for LLM detection and response systems that complement or even replace LLM firewalls.
The same approach will likely accelerate when multi-modal LLM usage expands, where scanning for more complex attacks becomes critical without compromising the performance that customers expect. OpenAI seems to be moving in this direction, adding asynchronous security scanning in their toolbox.
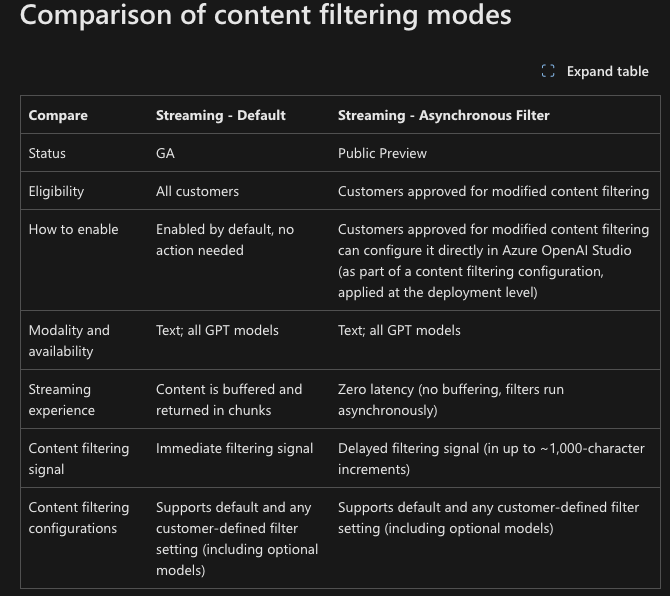
Azure Content Filtering Service with Asynchronous Filter in Preview
We're also seeing early adoption by other vendors. For instance, Microsoft has introduced an asynchronous scanning solution which is currently in preview, though we are still waiting to see other cloud providers like AWS, with Bedrock, follow suit with out-of-line scanning. Other foundational model providers, such as Anthropic, have also been known to ban users, and we anticipate that these vendors will increasingly adopt more comprehensive out-of-line threat scanning and response mechanisms, leading to more effective blocking or banning of problematic users.
As LLM capabilities grow and user interactions scale, security scanning will need to balance both in-line and out-of-line approaches. The more sophisticated an LLM becomes, the more complex in-line scanning will be with the gateway or reverse proxy approach, as it must evaluate an expanding and wider range of potential threats before passing the prompt to the model. And this doesn't even account for scanning the output before delivering it back to the user.
Some scanners, especially those tailored to multi-modal LLMs and relevant types of threats, will require significant compute resources, further complicating scaling efforts. Running more scanners will effectively drive up costs and increase latency, making it difficult to scale efficiently. If you also factor in the accuracy challenges of probabilistic classifiers, you encounter the same trilemma of cost, latency, and accuracy, we discussed in our earlier article on firewalls.
The clear need here is for a scalable, future-proof security solution for LLMs. Out-of-line threat detection and response will be key to achieving this, ensuring enterprise-level LLM security without sacrificing LLM application performance.