Secure by Design
Learn more 
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
Connect with Us
MLSecOps Community
Join a growing community of AI security practitioners.
Huntr
Join the world’s first bug bounty platform for AI/ML.
Follow us on LinkedIn for the latest company updates and content.
MLSecOps Podcast New Episode

Hacktivity Leaderboard
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI

If 2023 was the opening act for LLMs at the enterprise, then 2024 will be the main performance aimed at scaled production use-cases, increased investments and initial ROI to enterprises. This is already shown within projections of spending at the corporate level in LLMs, indicating a growth of 2.5x from $7M in 2023 to $18M in 2024. This is underpinned by the widespread embrace of the potential of LLMs by enterprises across use-cases such as enterprise knowledge management, text summarization, external chatbots, and recommendation algorithms. This adoption pattern is characterized by a split in usage between LLM solutions provided by third-party vendors, such as GitHub Copilot and JetBrains, and the internal application build pattern using API-based models (GPT-4.5, Claude, etc.) or internally deployed open-source LLMs (e.g. Mistral, LlaMa-2, etc.). Yet, most of the applications built have been predominantly confined to internal use-cases, driven by concerns over security and data protection in customer-facing use-cases.
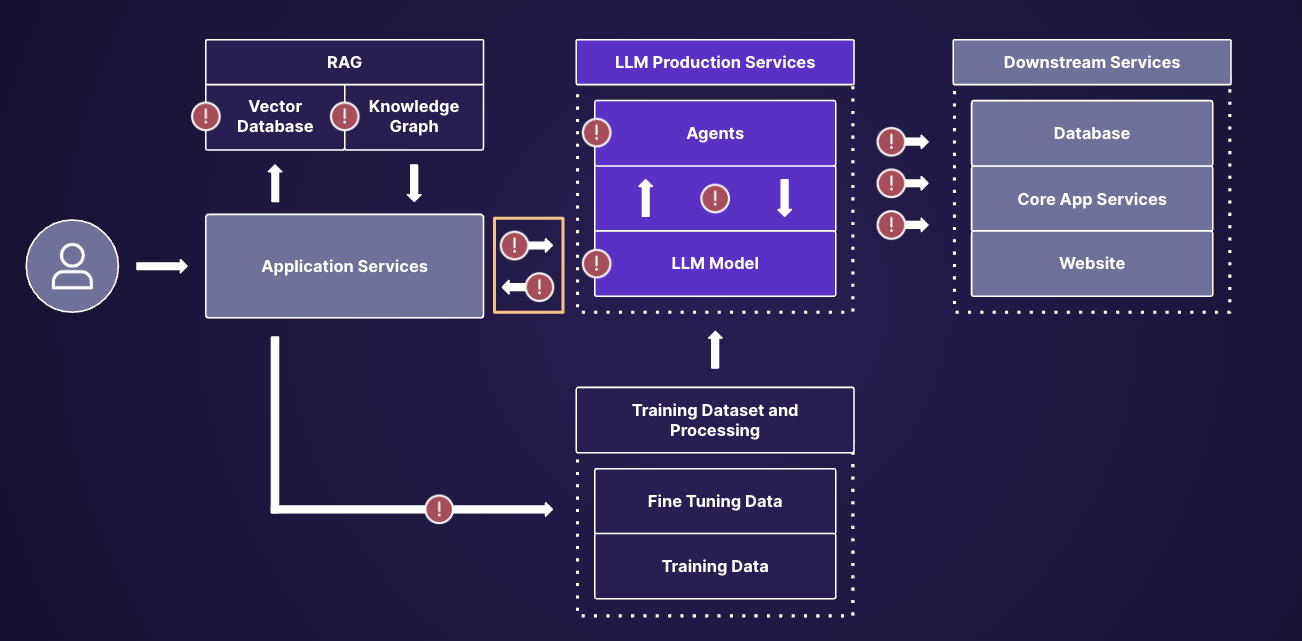
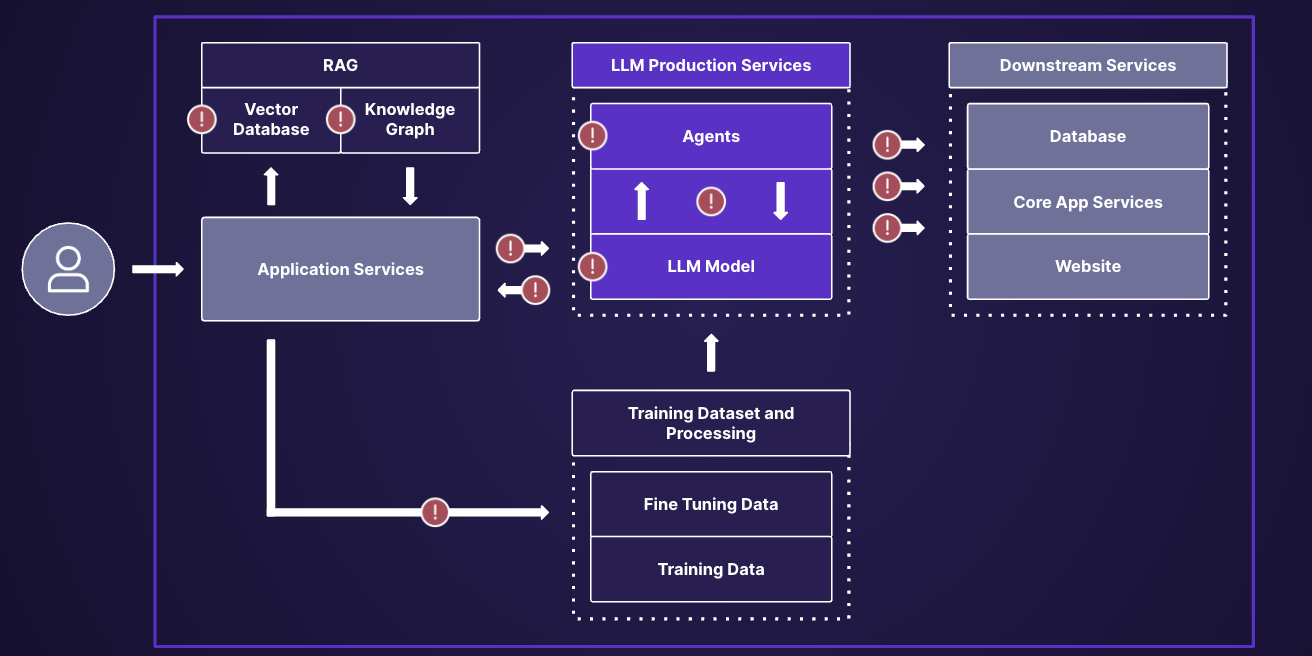
As companies were heavily investing and rushing applications to production without any security, we have seen several cases hit the news wire in 2023, some with real-world implications. These mainly included external chatbots divulging offensive content, misleading users, or being entirely vulnerable to jailbreak and prompt injection attacks. In some cases, it led to embarrassing news articles, in others, it led to a lost lawsuit. While these attacks were in many cases harmless beyond perceived brand damage, it is a premonition of what the future holds. We expect the damage blast radius of these attacks to expand significantly as upstream and downstream services, such as RAG, and Agents, become more readily adopted. Current attacks show the relative ease at which one can force the model to do what it shouldn’t be doing.
As these models get connected to downstream systems and have access to upstream data for augmentation, we will see real-world damage originate from excess privileges and unauthorized data access from these. Several researchers have already created complex proof of concept attacks with agents where they unleashed a self-replicating prompt injection in an email agent. Essentially, the prompt injection embedded in an email sent to a vulnerable user with an email agent led the agent to send the same prompt injection to all his contacts, some who may run the very same email agent. As education started to catch up with LLM app builders, we saw the emergence of solutions that could meet in-line security for LLMs. Enter LLM Firewalls.

You can think of an LLM firewall as a reverse proxy that sits in between the application and the different LLMs it interfaces with. It acts as a real-time evaluator, using multiple scanners, to detect security risks ranging from sensitive data leakage, adversarial prompt attacks, and integrity breaches. Our very own LLM Guard, which was initially released over summer 2023, was built after our understanding that there was not a single open source solution that could democratize security to developers and companies building enterprise-scale LLM applications with security built-in from day 0. Besides that, it was very clear to us that the concept of LLM Firewalls would become a heavily commoditised space over time which made us double down on our open source approach. The latter was reflected in the pace (1-3 every single week since September 2023) at which new companies were launched with little to no differentiation from LLM Guard. In fact, we learned that several companies have been relying on our toolkit as a basis for their closed source product. In one case, we even came across a company that raised funding based on outright copying the toolkit which became evident based on the 1:1 documentation they had public.
Nevertheless, since our release in summer 2023, we are proud that our toolkit has been recognized by a Google Patch Reward and is in use securing a broad set of enterprise LLM applications, striking a leading balance between cost, latency, and accuracy. Today, our toolkit with over +35 input and output scanners has become the open source market standard with our scanners having been downloaded over 2.5M times within 30 days of its initial release. We have also become the default prompt injection scanner for leading development frameworks such as Langchain, and LiteLLM.
Even though LLM Guard serves as a great entry point for companies aiming to build and deploy LLMs to production securely, LLM Firewalls as a concept and product is insufficient as a security solution considering the expanding capabilities and needs for corporates building and deploying LLM applications at scale. Some vendors further augment their firewall solution with a browser plugin that scans browser-accessed, yet unauthorized LLMs (i.e. non-IT-issued LLM), for inputs and outputs. While Shadow AI, as it is often referred to, is a risk to enterprises, we believe it is a problem that will be solved by existing shadow IT vendors as companies will prohibit non-authorized usage within their AI policies.
As we mentioned before, the market is awash with heavily commoditized products that, while designed for security often manifests as mere toolkits, at best with a UI wrapper (i.e. dashboard), offering little in the way of actionable intelligence for security teams. This is reflected in the dashboard-centric interfaces that highlight symptoms without offering remedial actions further illustrating the disconnect between these tools and the practical needs of security professionals. Across the board, this showcases a design pattern with consumption aimed at AI engineers in the early stages of testing and building of LLM applications. At this stage, security teams may be merely happy with a testing report, yet at scale, as these applications will drive more value to the organization the ownership of security will be with the security team that will need to detect and respond to threats within millions of interactions in a time and cost-efficient manner.
As it stands today, these firewalls are not able to scale security in an efficient manner due to:
As we did the basic math on publicly available pricing of known LLM Firewall vendors based on a case study of Klarna’s external chatbot as a proxy, the cost of runtime security vs. the model runtime cost per prompt and response was several multiples more, ranging between 2.9-6.7x depending on the vendor. This showcases the lack of sustainability of closed LLM firewalls with regard to the trilemma of cost, accuracy, and latency.
In a great article by Nico Popp, he describes how the emergence and respective challenges of LLM firewalls are reminiscent of the early days of Cloud Access Security Brokers (CASB). Similarly, LLM Firewalls are perceived as the current best strategy to secure LLM applications, yet they are shortsighted when considering the performance degradation at scale. As the adoption of cloud expanded exponentially, Nico shared how many startups were trying to resolve the CASB challenge of managing large volumes of data for inline, synchronous inspection for DLP yet all the approaches would eventually fail to scale effectively, given the amount of volume that needed to be scanned over a short time frame without impairing the user experience. In his case, at Symantec, the introduction of an async logging and monitoring solution allowed them to handle the increasing scale and complexity without the heavy lifting and challenges of real-time scanning. It allowed them to effectively handle the trade-off between latency and accuracy while significantly lowering the cost of security. It eventually was the right choice for Symantec, with this new product becoming a key revenue stream to the company.
A lot of parallels can be drawn from the CASB example. As we expect the volume of prompts, responses, and capabilities to expand significantly across enterprise LLM use-cases, corporations will need to be ready to scale security effectively. We already see that several companies we engage with are running millions of interactions per month within their LLM applications. The current cost equation, as mentioned before, in addition to the lack of actionability for security teams is not sustainable. We will see a shift from active blocking to LLM threat detection and response. This will involve expanded detection on multi-modality, and the upstream and downstream detection of threats within RAG and Agency.
At Protect AI, we are actively working with leading enterprises on future proofing the security of their LLMs in production and at scale. If you want to learn more about our early access program, sign up for a call here.