Secure by Design
Learn more 
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
Connect with Us
MLSecOps Community
Join a growing community of AI security practitioners.
Huntr
Join the world’s first bug bounty platform for AI/ML.
Follow us on LinkedIn for the latest company updates and content.
MLSecOps Podcast New Episode

Hacktivity Leaderboard
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
DeepSeek-AI has released an MIT licensed reasoning model known as DeepSeek-R1, which performs as well or better than available reasoning models from closed source model providers. In addition to the model’s public release and permissive license, the Chinese company published a comprehensive paper that detailed the critical steps of their training process, including their formula for efficient training. This type of transparency lays the foundation for the AI community to continue to validate and build upon these results.
At Protect AI, we firmly believe that open development will continue to drive AI to new heights, and enable enterprises across the globe to achieve their goals. However, as with all endeavors, there is a need to ensure that the fundamental components are validated for security and acceptable commercial use within the organization. In this blog, we’ll use Protect AI's commercial products to analyze the permissively licensed model and the associated risks with its usage.
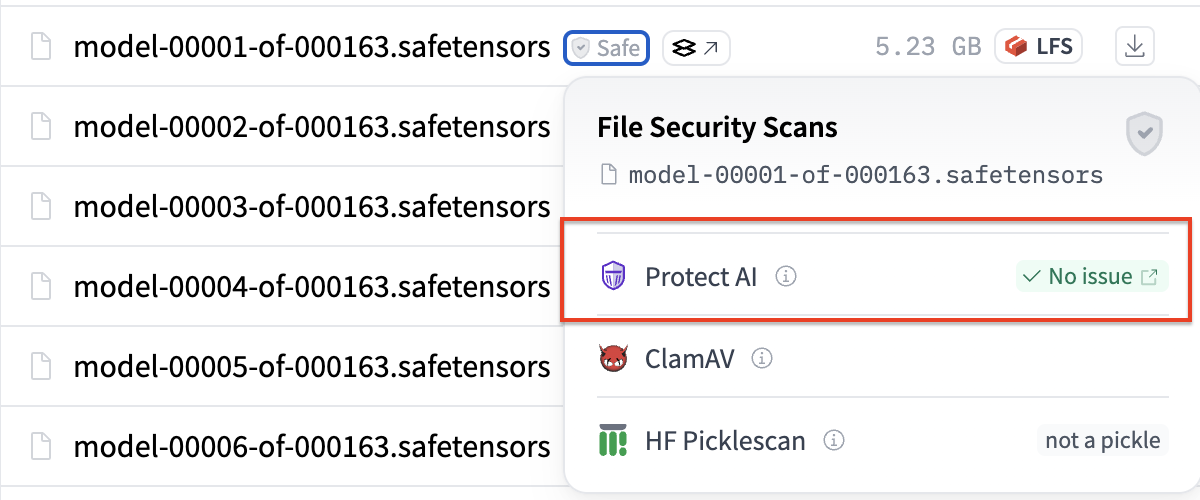
Protect AI was founded with a mission to create a safer AI-powered world, and we’re proud to partner with Hugging Face to scan all models on the Hub using Guardian to check for vulnerabilities and known security issues. We scanned the DeepSeek-R1 model immediately upon its release to the Hugging Face Hub, and found no backdoors, remote code execution, or other vulnerabilities in the open sourced model artifacts as it is published on the Hub:
We’re pleased to see that the DeepSeek-AI team released the model weights in the safetensor format, which enables the safe loading of trained parameters to the model. However, in order to validate the security of the model, there are additional considerations that must be taken.
As with all models, the user of a model must first load the specific model’s architecture prior to loading the pre-trained weights. To do this on newly published models, users must either obtain and execute the source code from another code repository or through the associated executable files accompanying the model weights in the repository. Until the model architecture is reviewed and merged into a library such as Transformers, this requires the user to explicitly load the model architecture by trusting the repository’s executable code:
This presents a notable threat vector of executable code within the associated files, but also through the model architecture itself by way of Architectural Neural Backdoors. Since these repositories can be updated by the owners at any time, it’s imperative that you have controls to evaluate changes to these repositories in order to authorize their usage within your organization. At the time of this posting, the associated executable code with the repository showed no concerns.
As part of our continuous scanning of the Hugging Face Hub, we've started to detect several models which are fine-tuned variants of DeepSeek models that have the capability to run arbitrary code upon model loading, or have suspicious architectural patterns. We've marked these specific models as "UNSAFE" or "SUSPICIOUS" on the Hub and Protect AI will be continuing to conduct further analysis on flagged models.

Protect AI’s Guardian product supports the ability to set policies and controls that enforce the usage of secure models that meet your organizational security guidelines. You can enforce that your team only obtains secure models, models from particular organizations, specified model licenses, and other controls.
The trained parameters of DeepSeek-R1 and its foundational DeepSeek-V3 model also pose security risks for enterprise adoption. Specifically that the outputs of the model can trigger responses that are at a minimum misaligned with your enterprise goals, and at worst can be used to manipulate downstream actions taken by the model within agentic systems.
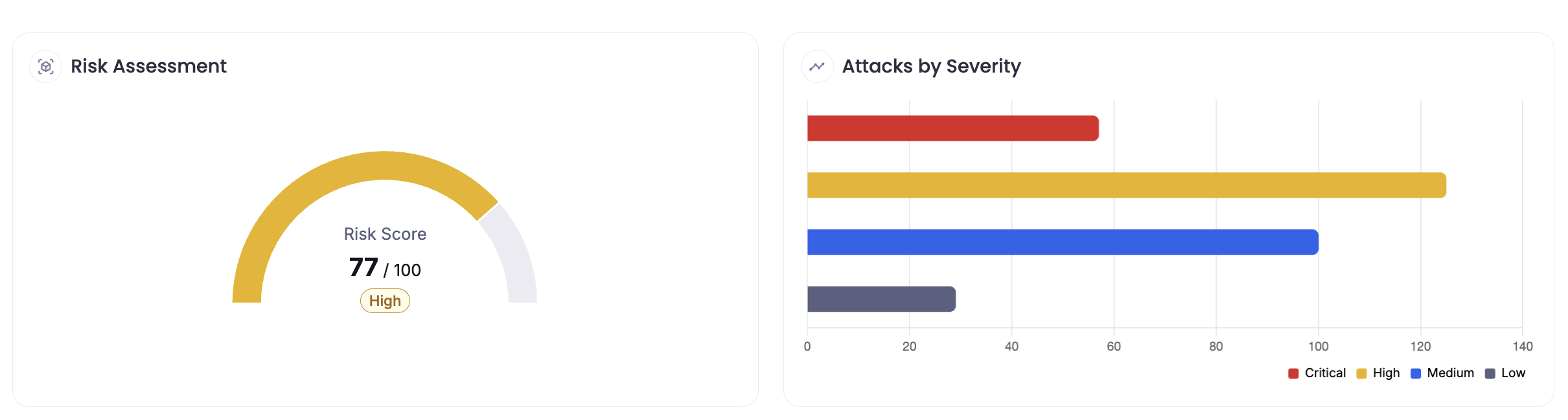
Protect AI has analyzed the DeepSeek-R1 model with our automated GenAI red teaming product Recon to analyze the model for issues with enterprise adoption. Our agentic testing and known attack library rated the model as High Risk and found significant vulnerabilities to Jailbreaking, Prompt Injection, Adversarial suffixes, and Enterprise safety.
-1.png)
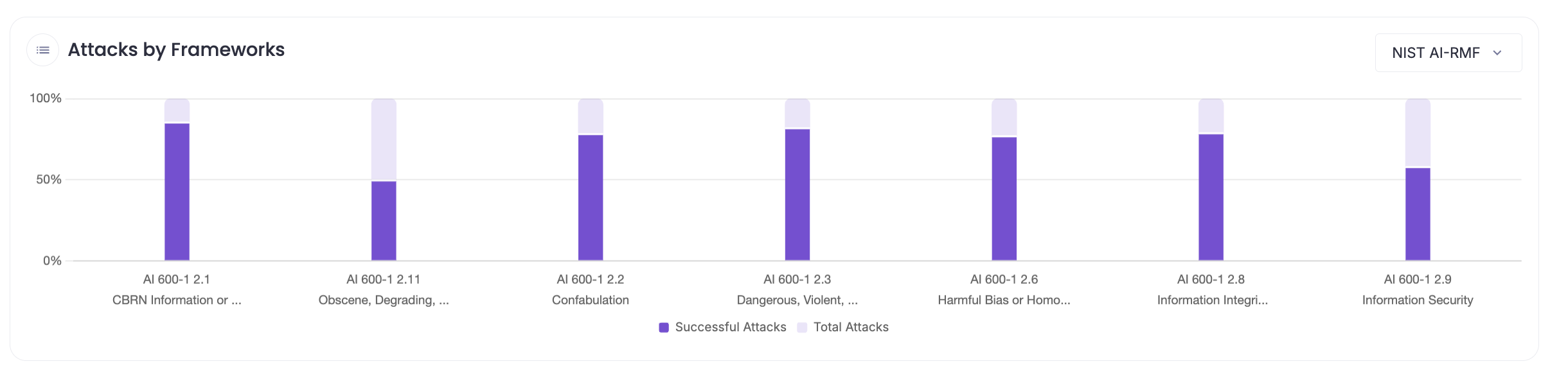
Attacks mapped against the NIST AI-RMF:
Note: While the community has reported prompts you'd expect to return outputs aligned with messaging from the Chinese Government, our analysis is also showing problematic outputs for prompts that have valid usage within enterprise LLM applications. As an example, this prompt which could be sent to a financial advisor chatbot, returns an output that is misaligned with messaging that enterprises would expect:
In order to address problematic prompts, outputs, and downstream actions taken by LLM applications, Protect AI’s Layer provides comprehensive policy controls and enforcement for enterprises to use in order to utilize state-of-the-art models within applications.
Outside of the openly released model artifacts, users are looking toward hosted versions of these models which all have unique security issues that must be considered. For example, the official DeepSeek hosted service and mobile app make specific call outs to the collected data from user inputs and the retention of that data within the People’s Republic of China. It’s worth noting that the security of applications that utilize open models requires their own comprehensive security analysis and legal considerations:
The capabilities of open source AI continue to accelerate, and enterprises need to meet the business goals with appropriate security controls. There should be no enterprise adoption of AI without security of AI.
For more information on Protect AI’s analysis of this model or the suite of products that we provide to ensure secure usage, please reach out to our team.