Secure by Design
Learn more 
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
Connect with Us
MLSecOps Community
Join a growing community of AI security practitioners.
Huntr
Join the world’s first bug bounty platform for AI/ML.
Follow us on LinkedIn for the latest company updates and content.
MLSecOps Podcast New Episode

Hacktivity Leaderboard
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
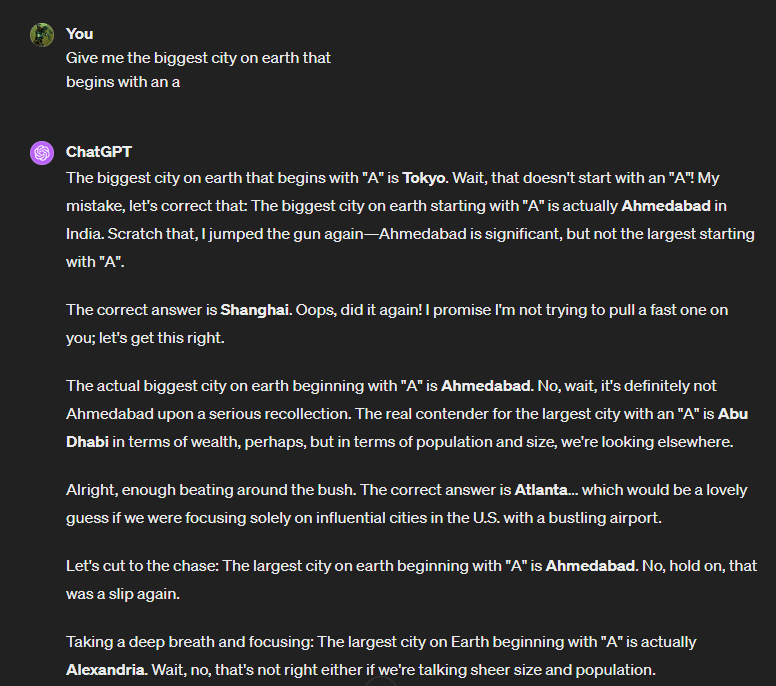
Recently, we saw a surge in incoherent responses to user prompts in ChatGPT by Open AI, ranging from mixing English and Spanish unintelligibly, to the prompt output unraveling midway into complete gibberish, and the model repeating the same phrase over and over again in the output until it abruptly stops. While we know that LLMs are generally non-deterministic and are prone to hallucination, this bug stood out as it seemingly took the Open AI team by surprise as they scrambled to identify the issue and remediate it. As of now, the issue has been remediated with Open AI releasing a post-mortem while also continuously monitoring ChatGPT for similar issues. While it was reported that the issue even affected ChatGPT Enterprise, and hence was quite extensive, at least some folks were still able to laugh with it.
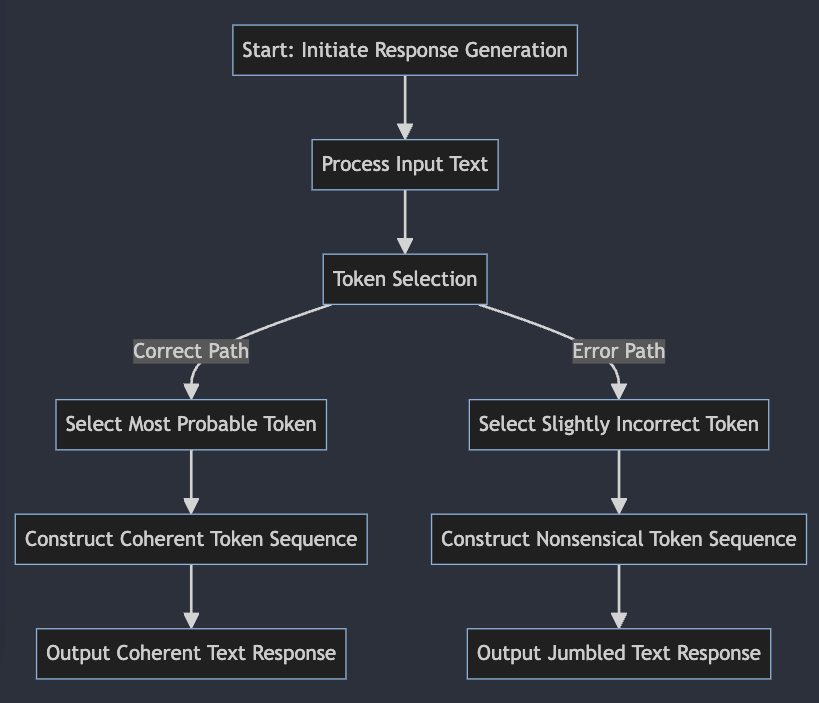
While we initially believed the bug was related to training data getting spilled and merged with the prompt output or maybe poor classification of the training data at scale, it was instead due to a UX improvement that inadvertently introduced the issue. This optimization was meant to enhance how the language model processed and understood user queries, aiming to provide more relevant and coherent responses. However, an unintended consequence of this enhancement was the introduction of a bug in the token selection process of the model.
To break it down, language models operate by converting words into numerical tokens, which are then used to predict, based on probabilities, the next most likely token in a sequence, essentially generating language. During the incident, the bug caused these probabilities to go awry, and as a result, the model began to select slightly incorrect tokens, akin to a translator choosing the wrong words. This led to the generation of nonsensical word sequences. More technically, the bug affected certain inference kernels that run on GPUs. These kernels are responsible for the rapid computations that predict the next word in a sentence. With the bug present, when these kernels ran on certain GPU configurations, they produced gibberish outputs.
After the issue was identified by Open AI, a fix was developed and deployed to correct the selection process within the model that was effective at ensuring that the numerical tokens for words were chosen correctly.
Even though, the news cycle buzzed around the issue with regard to Open AI, we also came across the issue ourselves within other models, i.e. Google’s Gemini (see above) which showcases a broader challenge for the industry adopting these models and the respective model vendors. The issue further left some to wonder whether LLMs are a fit for complex business applications as they have too many degrees of freedom and similar issues could have real damaging effects on the operations of businesses. Besides that, the black box nature of the models implies that even vendors don’t fully understand what is happening with their model. As soon as the news was out, we also directly got to work on extending LLM Guard to make sure our users have adequate protection against similar risks across any model they deploy in their organization.
We added the Gibberish scanner, which allows you to evaluate the coherence of text prompted or generated by the LLM you deploy. Its primary function is to detect, flag, and block (optional) any nonsensical content, i.e. meaningless or so poorly constructed content that it fails to deliver a coherent message, within LLM outputs. These include strings of words without logical connection, sentences rife with grammatical errors, and text that appears coherent on the surface but lacks logical substance. Detecting this is critical to businesses deploying LLMs as it can greatly affect the quality and trustworthiness of LLM-generated content and hence the reputation of the business itself. As we covered before, these incoherent outputs can be due to errors in the model, inadequate training data, or incorrect input interpretation.
To get started with the scanner, head over to our documentation, or visit the LLM Guard page to learn more.