Secure by Design
Learn more 
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
Connect with Us
MLSecOps Community
Join a growing community of AI security practitioners.
Huntr
Join the world’s first bug bounty platform for AI/ML.
Follow us on LinkedIn for the latest company updates and content.
MLSecOps Podcast New Episode

Hacktivity Leaderboard
A Prisma AIRS Power Play! Palo Alto Networks Completes Acquisition of Protect AI
NB Defense is a powerful Jupyter Lab Extension that enables data scientists to implement Shift Left Security in their ML development.
Jupyter Notebooks are pervasive in the world of data science and are used to develop ML workloads. They provide an interactive environment where data scientists can write and run code, as well as generate and share documents that contain code, visualizations, and text.
However, they can pose some significant security risks that organizations may not be aware of.
Because notebooks are often shared across teams, organizations, and sometimes uploaded to publicly accessible code repositories, they represent an entry point for attackers seeking to exploit an organization’s ML pipeline.
Our proprietary analysis on publicly available notebooks of major cloud providers and software companies in the ML industry has shown that their notebooks often contain sensitive data, such as authentication credentials which include tokens, API keys, etc., and/or PII (personally identifiable information) data. We see that this is especially true when notebooks are shared in a collaborative environment within organizations and across research domains, for example in fraud detection systems between finance and banking participants.
While some may have a perspective that ‘code is code’ and static in nature, there are major differences. One simple example is that ML code touches dynamic and live systems to see maximum performance, which inherently requires data scientists to have higher privileges. Sum these parts, and you have new threat surfaces for cybersecurity attacks.
With this in mind, we built NB Defense to focus on two specific areas for Shift Left Security in data science development: Secrets Detection and PII Detection.
Secrets generally refer to sensitive information such as authentication credentials, API keys, or tokens. A data scientist might hard code an API key during development when starting a new project. Hard coding the API key avoids the burden of creating an environmental variable or creating a configuration file. Instead, a data scientist can just start working with the API.
However, hard coding API keys is a major security risk, especially when multiple people may be working on the same codebase or sharing results. This is exactly what Jupyter Notebooks are designed to do, and part of their value. But, it’s also a security gap.
Once a malicious actor has access to a leaked API key, they could immediately have ‘authorized’ access to cloud resources and can, for example, launch a large number of compute instances. Consider the cost of firing up a host of expensive GPUs inside of your cloud environment!
Additionally, once inside your account, they can begin siphoning data from your data lakes which may contain data ranging from PII to proprietary corporate information. An attacker could also access existing and historical ML pipelines and artifacts, creating an opportunity for theft of some of the most valuable IP (intellectual property) your company has.
It’s easy to see how simply forgetting to remove an API key from code, initially used for rapid experimentation, can quickly morph into a multi-pronged attacked on an organizations’ entire infrastructure.
PII includes a person's name, phone number, email, social security number (SSN), etc., and is used in data science across a gamut of industries from finance to healthcare.
PII is typically used to train systems that require sensitive information for ML workloads such as personalized recommendations for products on Netflix and Amazon Prime, or fraud detection algorithms employed by financial institutions. This critical element in building an ML model is also inherently a security risk.
A typical ML workflow may pull customer data from a datastore, like AWS S3 buckets, into a notebook before manipulating that data with a library such as Pandas for data cleaning and feature selection. To verify the data has undergone the relevant transformations, it is common to display portions of the DataFrame (i.e. df.head(),df.tail()).
This is where the risk exists: Cell output in Jupyter is not automatically cleared or reset between sessions. All the cell output could be present if running a notebook from start to finish. As a result, even if access between the notebook and the original datastore was severed, the notebook has 'memory' and is still showcasing the data!
Showcasing data, visualizations, and textual commentary is precisely what Jupyter notebooks are designed to do. However, it is the responsibility of the data scientist to ensure that the contents of the data doesn’t violate privacy regulations or (as has been seen many times from publicly announced breaches) inadvertently leaks training data used to develop a proprietary model.
Also, attackers armed with REGEX and access to public or compromised private repositories can easily wade through notebooks looking for key information like credit card numbers, SSNs, or even hyperparameters for models!
Against this backdrop, mishandling sensitive data leads to enterprise risks and legal liabilities in cases of regulatory violations (i.e. GDPR/HIPPA) and leads to the loss of trade secrets by leaking your training data sets.
Data scientists need to start embracing security practices in a way that maintains their need for access to live systems and production data sources while not constraining their ability to move quickly and continue innovating and experimenting.
NB Defense helps data scientists achieve this by unleashing “Shift Left Security” capabilities, native to their notebook development.
Shift Left Security is an approach which underscores integrating security into the earliest stages of the development process (e.g., planning, analysis, design) to reduce security breaches. This is different from traditional security methods which treat the need for security as a separate and distinct stage of software development often coming late in the development cycle.
While data scientists typically have some exposure to security best practices, they are mostly focused on statistical analysis and model building. Adopting Shift Left Security practices by using tools like NB Defense enables the best of both worlds: Focusing on modeling without worrying about security.
As the ML industry’s first Jupyter Lab extension capable of detecting Secrets and PII within Jupyter Notebooks, data science teams can enhance the quality and security of their AI/ML code base and safeguard sensitive data in a crucial asset of the ML software supply chain.
NB Defense deploys as a Jupyter extension working directly within your Jupyter environment. This gives you a low-friction user experience to scan notebooks for potential vulnerabilities prior to being checked in or shared.
After logging in, you’re directed to the “Getting Started” page that includes your unique NB Defense license key and instructions to install and use the tool locally as well as on ML platforms. Next, you will want to customize it for your needs.
NB Defense provides customizable settings for secrets and PII detection. With this new feature, users can easily toggle individual entities on and off for detection.
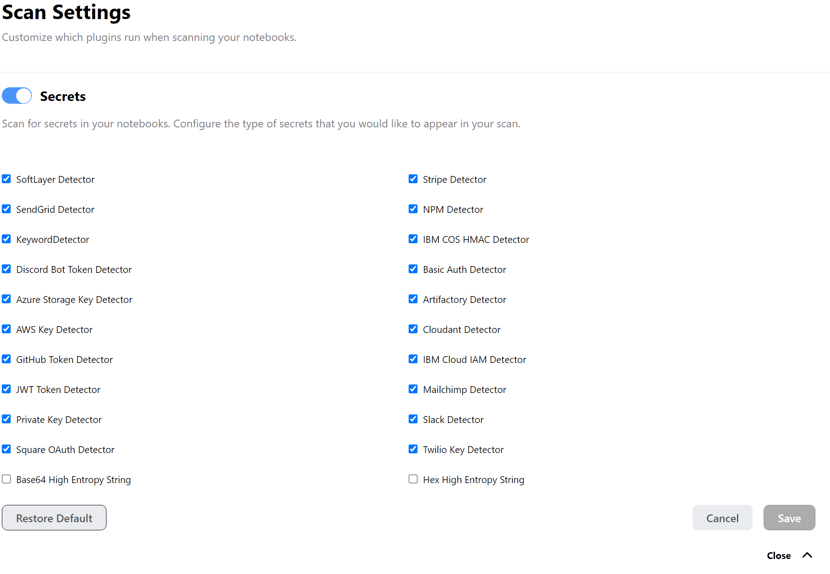
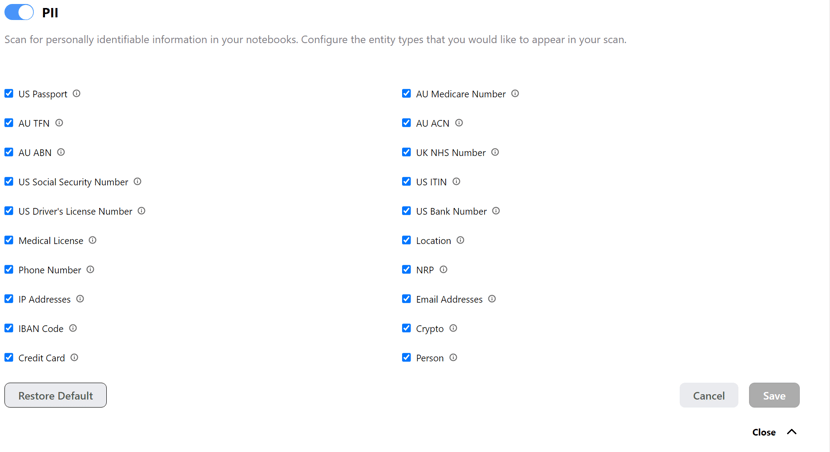
Easily identify and remediate potential risks with contextual help that underlines code cells and highlights output cells that contain PII and Secrets.
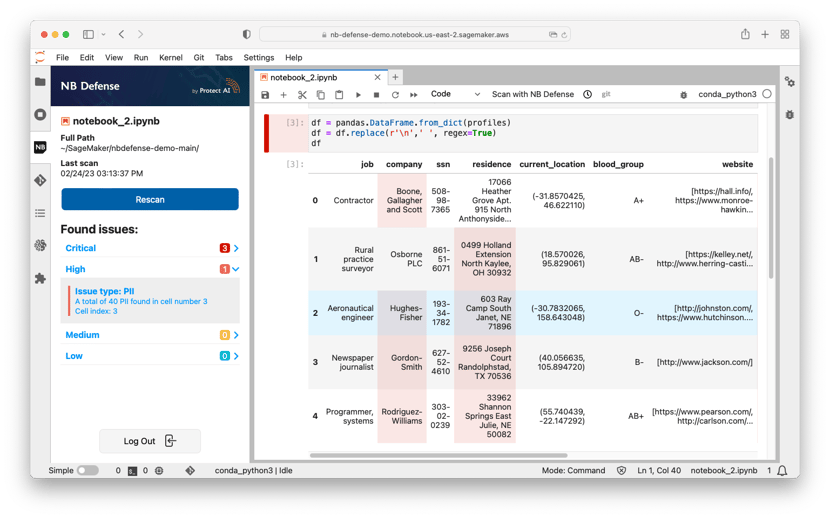
Protect AI is dedicated to developing tools that promote the adoption of MLSecOps within the machine learning community and NB Defense is just one step towards implementing MLSecOps. So, #ShiftLeftML with us, and advance MLSecOps by getting started with NB Defense, and learn more by joining our Slack community.



